

— DeepAI colorization
— Me@2020-11-25 04:39:20 PM
.
.
2020.11.25 Wednesday (c) All rights reserved by ACHK

— DeepAI colorization
— Me@2020-11-25 04:39:20 PM
.
.
2020.11.25 Wednesday (c) All rights reserved by ACHK
A First Course in String Theory
.
2.3 Lorentz transformations, derivatives, and quantum operators.
(b) Show that the objects 


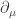
~~~
…
Denoting 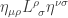
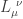
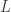
To avoid this bug, instead, we denote 
…
Using the Kronecker Delta and Einstein summation notation, we have
So
In other words,
— Me@2020-11-23 04:27:13 PM
.
One defines (as a matter of notation),
and may in this notation write
Now for a subtlety. The implied summation on the right hand side of
is running over a row index of the matrix representing 


— Wikipedia on Lorentz transformation
.
So
In other words,
.
Denote ![\displaystyle{[L^{-1}]^{\beta}_{~\mu}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B%5BL%5E%7B-1%7D%5D%5E%7B%5Cbeta%7D_%7B%7E%5Cmu%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
In other words,
.
The Lorentz transformation:
.
.
.
.
Now we consider 
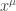
Since 
For notational simplicity, we write
Since
Since
![\displaystyle{ \begin{aligned} x^\nu &= [L^{-1}]^\nu_{~\beta} (x')^\beta \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++x%5E%5Cnu+%26%3D+%5BL%5E%7B-1%7D%5D%5E%5Cnu_%7B%7E%5Cbeta%7D+%28x%27%29%5E%5Cbeta+%5C%5C+++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
Therefore,
It is the same as the Lorentz transform for covariant vectors:
— Me@2020-11-23 04:27:13 PM
.
.
2020.11.24 Tuesday (c) All rights reserved by ACHK
In physics, a global symmetry is a symmetry that holds at all points in the spacetime under consideration, as opposed to a local symmetry which varies from point to point.
Global symmetries require conservation laws, but not forces, in physics.
— Wikipedia on Global symmetry
.
.
2020.11.22 Sunday ACHK
無額外論 7
.
The one in the mirror is your Light.
— Me@2011.06.24
.
Thou shalt have no other gods before Me.
— one of the Ten Commandments
.
God teach you through your mind; help you through your actions.
— Me@the Last Century
.
.
2020.11.21 Saturday (c) All rights reserved by ACHK
機遇創生論 1.6.6 | 十年 3.4
.
通用的極致,就是專業。而通用發展成極致的方法,有很多種。每種極致,就自成一門專業。通用是樹幹;專業是樹支。一支樹支的強壯與否,並不能保證,另一支樹支的健康。
那是否就代表,學生時代以後,就毋須再發展,通用知識或通用技能呢?
.
學生時代以後,工作時代中,仍然需要發展,通用知識或通用技能,從而維持自己的智能和體能,以防退化。例如,剛才所講的智力遊戲,我認為可以,避免老人家的腦部退化。
我那樣認為,是因為我看過一些老人家的訪問。有一位九十歲的女仕說,她透過玩手提遊戲機,保持頭腦的清醒靈活。
即使還未老年,只是步入中年,也應該多加留意,智能或體能上的退化。玩適當類型的電腦遊戲,可以保持反應的靈敏。什麼類型呢?
電腦遊戲有很多類型,主要有「建構」、「解謎」和「戰鬥任務」三種。「戰鬥任務」就可用來鍛鍊反應。那些遊戲會放你於,危險和緊急的處境。你當時必須有,敏捷和精準的身手,才可以完成任務,然後脫險。換句話說,那些遊戲亦同時訓練你,控制自己的心理,駕馭自己的恐懼。
同理,雖然一般的運動本身,例如掌上壓,並沒有什麼所謂的「用途」,但是,你正正需要這些「無用」的運動,去維持體能。
無論是體能和智能,如果沒有強大而穩定的主幹,就不會有健康的分支和茂盛的樹葉。
— Me@2020-11-16 04:55:18 PM
.
.
2020.11.20 Friday (c) All rights reserved by ACHK

— Me@2020-11-14 09:27:04 PM
.
.
2020.11.14 Saturday (c) All rights reserved by ACHK
Structure and Interpretation of Classical Mechanics
.
Ex 1.10 Higher-derivative Lagrangians
Derive Lagrange’s equations for Lagrangians that depend on accelerations. In particular, show that the Lagrange equations for Lagrangians of the form 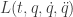

In general, these equations, first derived by Poisson, will involve the fourth derivative of 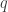
Varying the action
.
Let ![\displaystyle{h[q] = D^2 q}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7Bh%5Bq%5D+%3D+D%5E2+q%7D&bg=ffffff&fg=333333&s=0&c=20201002)
.
Chain rule of functional variation
Since variation commutes with integration,
By the chain rule of functional variation:
If
But is
The ![\displaystyle{L \circ \Gamma [.]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7BL+%5Ccirc+%5CGamma+%5B.%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
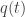


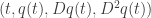
Since
Since 

Here is a trick for integration by parts:
As long as the boundary term
,
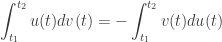
So if 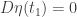
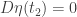
Since
By the principle of stationary action, ![\displaystyle{ \delta_\eta S[q] (t_1, t_2) = 0}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cdelta_%5Ceta+S%5Bq%5D+%28t_1%2C+t_2%29+%3D+0%7D&bg=ffffff&fg=333333&s=0&c=20201002)
Since this is true for any function 


.
Note:
The notation of the path function 
}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B%5CGamma%5Bq%5D%28t%29%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{\Gamma[q(t)]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B%5CGamma%5Bq%28t%29%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
The notation ![\displaystyle{\Gamma[q]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B%5CGamma%5Bq%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
The other notation ![\displaystyle{\Gamma[.]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B%5CGamma%5B.%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
— Me@2020-11-11 05:37:13 PM
.
.
2020.11.11 Wednesday (c) All rights reserved by ACHK
Logical arrow of time, 4.2
.
Memory is of the past.
The main point of memories or records is that without them, most of the past microstate information would be lost for a macroscopic observer forever.
For example, if a mixture has already reached an equilibrium state, we cannot deduce which previous microstate it is from, unless we have the memory of it.

This work is free and may be used by anyone for any purpose. Wikimedia Foundation has received an e-mail confirming that the copyright holder has approved publication under the terms mentioned on this page.
.
memory/record
~ some of the past microstate and macrostate information encoded in present macroscopic devices, such as paper, electronic devices, etc.
.
How come macroscopic time is cumulative?
.
Quantum states are unitary.
A quantum state in the present is evolved from one and only one quantum state at any particular time point in the past.
Also, that quantum state in the present will evolve to one and only one quantum state at any particular time point in the future.
.
Let
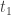

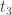
Also, let state 


.
State
Instead, just by knowing that
In other words, microstate does not require memory.
— Me@2020-10-28 10:26 AM
.
.
2020.11.02 Monday (c) All rights reserved by ACHK
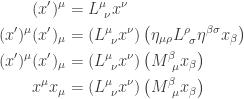

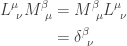

![\displaystyle{ \begin{aligned} M^{\beta}_{~\mu} &= [L^{-1}]^{\beta}_{~\mu} \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++M%5E%7B%5Cbeta%7D_%7B%7E%5Cmu%7D+%26%3D+%5BL%5E%7B-1%7D%5D%5E%7B%5Cbeta%7D_%7B%7E%5Cmu%7D+%5C%5C+++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} \eta_{\mu \rho} L^\rho_{~\sigma} \eta^{\nu \sigma} &= [L^{-1}]^{\beta}_{~\mu} \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D++++%5Ceta_%7B%5Cmu+%5Crho%7D+L%5E%5Crho_%7B%7E%5Csigma%7D+%5Ceta%5E%7B%5Cnu+%5Csigma%7D+%26%3D+%5BL%5E%7B-1%7D%5D%5E%7B%5Cbeta%7D_%7B%7E%5Cmu%7D+%5C%5C+++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)



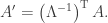
![\displaystyle{ \begin{aligned} \eta_{\mu \rho} L^\rho_{~\sigma} \eta^{\beta \sigma} &= [L^{-1}]^{\beta}_{~\mu} \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D++++%5Ceta_%7B%5Cmu+%5Crho%7D+L%5E%5Crho_%7B%7E%5Csigma%7D+%5Ceta%5E%7B%5Cbeta+%5Csigma%7D+%26%3D+%5BL%5E%7B-1%7D%5D%5E%7B%5Cbeta%7D_%7B%7E%5Cmu%7D+%5C%5C+++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)

![\displaystyle{ \begin{aligned} N^{~\beta}_{\mu} &= M^{\beta}_{~\mu} \\ [N^T] &= [M] \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++N%5E%7B%7E%5Cbeta%7D_%7B%5Cmu%7D+%26%3D+M%5E%7B%5Cbeta%7D_%7B%7E%5Cmu%7D+%5C%5C+++%5BN%5ET%5D+%26%3D+%5BM%5D+%5C%5C+++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)

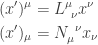
![\displaystyle{ \begin{aligned} x^\mu &= [L^{-1}]^\mu_{~\nu} (x')^\nu \\ (x')_\mu &= M^{\nu}_{~\mu} x_\nu \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++x%5E%5Cmu+%26%3D+%5BL%5E%7B-1%7D%5D%5E%5Cmu_%7B%7E%5Cnu%7D+%28x%27%29%5E%5Cnu+%5C%5C+++%28x%27%29_%5Cmu+%26%3D+M%5E%7B%5Cnu%7D_%7B%7E%5Cmu%7D+x_%5Cnu+%5C%5C+++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} x^\mu &= [L^{-1}]^\mu_{~\nu} (x')^\nu \\ (x')_\mu &= [L^{-1}]^{\nu}_{~\mu} x_\nu \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++x%5E%5Cmu+%26%3D+%5BL%5E%7B-1%7D%5D%5E%5Cmu_%7B%7E%5Cnu%7D+%28x%27%29%5E%5Cnu+%5C%5C+++%28x%27%29_%5Cmu+%26%3D+%5BL%5E%7B-1%7D%5D%5E%7B%5Cnu%7D_%7B%7E%5Cmu%7D+x_%5Cnu+%5C%5C+++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
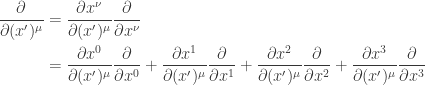


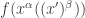

![\displaystyle{ \begin{aligned} \frac{\partial f}{\partial (x')^\mu} &= \sum_{\nu = 0}^4 \frac{\partial}{\partial (x')^\mu} \left[ \sum_{\beta = 0}^4 [L^{-1}]^\nu_{~\beta} (x')^\beta \right] \frac{\partial f}{\partial x^\nu} \\ &= \sum_{\nu = 0}^4 \sum_{\beta = 0}^4 [L^{-1}]^\nu_{~\beta} \frac{\partial (x')^\beta}{\partial (x')^\mu} \frac{\partial f}{\partial x^\nu} \\ &= \sum_{\nu = 0}^4 \sum_{\beta = 0}^4 [L^{-1}]^\nu_{~\beta} \delta^\beta_\mu \frac{\partial f}{\partial x^\nu} \\ &= \sum_{\nu = 0}^4 [L^{-1}]^\nu_{~\mu} \frac{\partial f}{\partial x^\nu} \\ &= [L^{-1}]^\nu_{~\mu} \frac{\partial f}{\partial x^\nu} \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+%28x%27%29%5E%5Cmu%7D+++%26%3D+%5Csum_%7B%5Cnu+%3D+0%7D%5E4+%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+%28x%27%29%5E%5Cmu%7D+%5Cleft%5B++%5Csum_%7B%5Cbeta+%3D+0%7D%5E4+%5BL%5E%7B-1%7D%5D%5E%5Cnu_%7B%7E%5Cbeta%7D+%28x%27%29%5E%5Cbeta+%5Cright%5D+%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+x%5E%5Cnu%7D+%5C%5C+++%26%3D+%5Csum_%7B%5Cnu+%3D+0%7D%5E4+%5Csum_%7B%5Cbeta+%3D+0%7D%5E4+%5BL%5E%7B-1%7D%5D%5E%5Cnu_%7B%7E%5Cbeta%7D+%5Cfrac%7B%5Cpartial+%28x%27%29%5E%5Cbeta%7D%7B%5Cpartial+%28x%27%29%5E%5Cmu%7D+%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+x%5E%5Cnu%7D+%5C%5C+++%26%3D+%5Csum_%7B%5Cnu+%3D+0%7D%5E4+%5Csum_%7B%5Cbeta+%3D+0%7D%5E4+%5BL%5E%7B-1%7D%5D%5E%5Cnu_%7B%7E%5Cbeta%7D+%5Cdelta%5E%5Cbeta_%5Cmu+%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+x%5E%5Cnu%7D+%5C%5C+++%26%3D+%5Csum_%7B%5Cnu+%3D+0%7D%5E4+%5BL%5E%7B-1%7D%5D%5E%5Cnu_%7B%7E%5Cmu%7D+%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+x%5E%5Cnu%7D+%5C%5C+++%26%3D+%5BL%5E%7B-1%7D%5D%5E%5Cnu_%7B%7E%5Cmu%7D+%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+x%5E%5Cnu%7D+%5C%5C+++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} \frac{\partial}{\partial (x')^\mu} &= [L^{-1}]^\nu_{~\mu} \frac{\partial}{\partial x^\nu} \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+%28x%27%29%5E%5Cmu%7D+%26%3D+%5BL%5E%7B-1%7D%5D%5E%5Cnu_%7B%7E%5Cmu%7D+%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+x%5E%5Cnu%7D+%5C%5C+++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} (x')_\mu &= [L^{-1}]^{\nu}_{~\mu} x_\nu \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++%28x%27%29_%5Cmu+%26%3D+%5BL%5E%7B-1%7D%5D%5E%7B%5Cnu%7D_%7B%7E%5Cmu%7D+x_%5Cnu+%5C%5C+++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{D^2(\partial_3L \circ \Gamma[q]) - D(\partial_2 L \circ \Gamma[q]) + \partial_1 L \circ \Gamma[q] = 0}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7BD%5E2%28%5Cpartial_3L+%5Ccirc+%5CGamma%5Bq%5D%29+-+D%28%5Cpartial_2+L+%5Ccirc+%5CGamma%5Bq%5D%29+%2B+%5Cpartial_1+L+%5Ccirc+%5CGamma%5Bq%5D+%3D+0%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} S[q] (t_1, t_2) &= \int_{t_1}^{t_2} L \circ \Gamma [q] \\ \eta(t_1) &= \eta(t_2) = 0 \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++S%5Bq%5D+%28t_1%2C+t_2%29+%26%3D+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+L+%5Ccirc+%5CGamma+%5Bq%5D+%5C%5C+++%5Ceta%28t_1%29+%26%3D+%5Ceta%28t_2%29+%3D+0+%5C%5C+++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} \delta_\eta S[q] (t_1, t_2) &= 0 \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++%5Cdelta_%5Ceta+S%5Bq%5D+%28t_1%2C+t_2%29+%26%3D+0+%5C%5C+++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} \delta_\eta S[q] (t_1, t_2) &= \int_{t_1}^{t_2} \delta_\eta \left( L \circ \Gamma [q] \right) \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++%5Cdelta_%5Ceta+S%5Bq%5D+%28t_1%2C+t_2%29+%26%3D+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+%5Cdelta_%5Ceta+%5Cleft%28+L+%5Ccirc+%5CGamma+%5Bq%5D+%5Cright%29+%5C%5C+++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} \delta_\eta I [q] &= \eta \\ \delta_\eta g[q] &= D \eta~~~\text{with}~~~g[q] = Dq \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++++%5Cdelta_%5Ceta+I+%5Bq%5D+%26%3D+%5Ceta+%5C%5C++%5Cdelta_%5Ceta+g%5Bq%5D+%26%3D+D+%5Ceta%7E%7E%7E%5Ctext%7Bwith%7D%7E%7E%7Eg%5Bq%5D+%3D+Dq+%5C%5C+++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} \delta_\eta h[q] &= \lim_{\epsilon \to 0} \frac{h[q+\epsilon \eta] - h[q]}{\epsilon} \\ &= \lim_{\epsilon \to 0} \frac{D^2 (q+\epsilon \eta) - D^2 q}{\epsilon} \\ &= \lim_{\epsilon \to 0} \frac{D^2 q + D^2 \epsilon \eta - D^2 q}{\epsilon} \\ &= \lim_{\epsilon \to 0} \frac{D^2 \epsilon \eta}{\epsilon} \\ &= D^2 \eta \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++%5Cdelta_%5Ceta+h%5Bq%5D+++%26%3D+%5Clim_%7B%5Cepsilon+%5Cto+0%7D+%5Cfrac%7Bh%5Bq%2B%5Cepsilon+%5Ceta%5D+-+h%5Bq%5D%7D%7B%5Cepsilon%7D+%5C%5C+++%26%3D+%5Clim_%7B%5Cepsilon+%5Cto+0%7D+%5Cfrac%7BD%5E2+%28q%2B%5Cepsilon+%5Ceta%29+-+D%5E2+q%7D%7B%5Cepsilon%7D+%5C%5C+++%26%3D+%5Clim_%7B%5Cepsilon+%5Cto+0%7D+%5Cfrac%7BD%5E2+q+%2B+D%5E2+%5Cepsilon+%5Ceta+-+D%5E2+q%7D%7B%5Cepsilon%7D+%5C%5C+++%26%3D+%5Clim_%7B%5Cepsilon+%5Cto+0%7D+%5Cfrac%7BD%5E2+%5Cepsilon+%5Ceta%7D%7B%5Cepsilon%7D+%5C%5C+++%26%3D+D%5E2+%5Ceta+%5C%5C+++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} \Gamma [q] (t) &= (t, q(t), D q(t), D^2 q(t)) \\ \delta_\eta \Gamma [q] (t) &= (0, \eta (t), D \eta (t), D^2 \eta (t)) \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++%5CGamma+%5Bq%5D+%28t%29+%26%3D+%28t%2C+q%28t%29%2C+D+q%28t%29%2C+D%5E2+q%28t%29%29+%5C%5C++%5Cdelta_%5Ceta+%5CGamma+%5Bq%5D+%28t%29+%26%3D+%280%2C+%5Ceta+%28t%29%2C+D+%5Ceta+%28t%29%2C+D%5E2+%5Ceta+%28t%29%29+%5C%5C++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} &\delta_\eta F[g[q]] \\ &= \delta_\eta (F \circ g)[q] \\ &= \delta_{ \left( \delta_\eta g[q] \right)} F[g] \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+%26%5Cdelta_%5Ceta+F%5Bg%5Bq%5D%5D+%5C%5C+++%26%3D+%5Cdelta_%5Ceta+%28F+%5Ccirc+g%29%5Bq%5D+%5C%5C+++%26%3D+%5Cdelta_%7B+%5Cleft%28+%5Cdelta_%5Ceta+g%5Bq%5D+%5Cright%29%7D+F%5Bg%5D+%5C%5C+%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} \delta_\eta S[q] (t_1, t_2) &= \delta_\eta \int_{t_1}^{t_2} L \circ \Gamma [q] \\ &= \int_{t_1}^{t_2} \delta_\eta \left( L \circ \Gamma [q] \right) \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++%5Cdelta_%5Ceta+S%5Bq%5D+%28t_1%2C+t_2%29+++%26%3D+%5Cdelta_%5Ceta+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+L+%5Ccirc+%5CGamma+%5Bq%5D+%5C%5C+++%26%3D+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+%5Cdelta_%5Ceta+%5Cleft%28+L+%5Ccirc+%5CGamma+%5Bq%5D+%5Cright%29+%5C%5C+++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} \delta_\eta L \circ \Gamma [q] = \delta_{ \left( \delta_\eta \Gamma[q] \right)} L[\Gamma[q]] \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++%5Cdelta_%5Ceta+L+%5Ccirc+%5CGamma+%5Bq%5D+%3D+%5Cdelta_%7B+%5Cleft%28+%5Cdelta_%5Ceta+%5CGamma%5Bq%5D+%5Cright%29%7D+L%5B%5CGamma%5Bq%5D%5D+%5C%5C+++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} \delta_\eta \left( L \circ \Gamma [q] \right) = \left( DL \circ \Gamma[q] \right) \delta_\eta \Gamma[q] \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++%5Cdelta_%5Ceta+%5Cleft%28+L+%5Ccirc+%5CGamma+%5Bq%5D+%5Cright%29+%3D+%5Cleft%28+DL+%5Ccirc+%5CGamma%5Bq%5D+%5Cright%29+%5Cdelta_%5Ceta+%5CGamma%5Bq%5D+%5C%5C+++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} L \circ \Gamma [q] = L(t, q(t), Dq(t), D^2 q(t)) \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++L+%5Ccirc+%5CGamma+%5Bq%5D+%3D+L%28t%2C+q%28t%29%2C+Dq%28t%29%2C+D%5E2+q%28t%29%29+%5C%5C+++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} \delta_\eta \left( L \circ \Gamma [q] \right) = \left( DL \circ \Gamma[q] \right) \delta_\eta \Gamma[q] \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++%5Cdelta_%5Ceta+%5Cleft%28+L+%5Ccirc+%5CGamma+%5Bq%5D+%5Cright%29+++%3D+%5Cleft%28+DL+%5Ccirc+%5CGamma%5Bq%5D+%5Cright%29+%5Cdelta_%5Ceta+%5CGamma%5Bq%5D+%5C%5C+++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} &\delta_\eta S[q] (t_1, t_2) \\ &= \int_{t_1}^{t_2} \delta_\eta L \circ \Gamma [q] \\ &= \int_{t_1}^{t_2} \left( D \left( L \circ \Gamma[q] \right) \right) \delta_\eta \Gamma[q] \\ &= \int_{t_1}^{t_2} \left( D \left( L(t, q, D q, D^2 q) \right) \right) (0, \eta (t), D \eta (t), D^2 \eta (t)) \\ &= \int_{t_1}^{t_2} \left[ \partial_0 L \circ \Gamma[q], \partial_1 L \circ \Gamma[q], \partial_2 L \circ \Gamma[q], \partial_3 L \circ \Gamma[q] \right] (0, \eta (t), D \eta (t), D^2 \eta (t)) \\ &= \int_{t_1}^{t_2} (\partial_1 L \circ \Gamma[q]) \eta + (\partial_2 L \circ \Gamma[q]) D \eta + (\partial_3 L \circ \Gamma[q]) D^2 \eta \\ &= \int_{t_1}^{t_2} (\partial_1 L \circ \Gamma[q]) \eta + \left[ \left. (\partial_2 L \circ \Gamma[q]) \eta \right|_{t_1}^{t_2} - \int_{t_1}^{t_2} D(\partial_2 L \circ \Gamma[q]) \eta \right] + \int_{t_1}^{t_2} (\partial_3 L \circ \Gamma[q]) D^2 \eta \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++%26%5Cdelta_%5Ceta+S%5Bq%5D+%28t_1%2C+t_2%29+%5C%5C++%26%3D+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+%5Cdelta_%5Ceta+L+%5Ccirc+%5CGamma+%5Bq%5D+%5C%5C+++%26%3D+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+%5Cleft%28+D+%5Cleft%28+L+%5Ccirc+%5CGamma%5Bq%5D+%5Cright%29+%5Cright%29+%5Cdelta_%5Ceta+%5CGamma%5Bq%5D++%5C%5C+++%26%3D+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+%5Cleft%28+D+%5Cleft%28+L%28t%2C+q%2C+D+q%2C+D%5E2+q%29+%5Cright%29+%5Cright%29+%280%2C+%5Ceta+%28t%29%2C+D+%5Ceta+%28t%29%2C+D%5E2+%5Ceta+%28t%29%29++%5C%5C+++%26%3D+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+%5Cleft%5B+%5Cpartial_0+L+%5Ccirc+%5CGamma%5Bq%5D%2C+%5Cpartial_1+L+%5Ccirc+%5CGamma%5Bq%5D%2C+%5Cpartial_2+L+%5Ccirc+%5CGamma%5Bq%5D%2C+%5Cpartial_3+L+%5Ccirc+%5CGamma%5Bq%5D+%5Cright%5D+%280%2C+%5Ceta+%28t%29%2C+D+%5Ceta+%28t%29%2C+D%5E2+%5Ceta+%28t%29%29++%5C%5C+++%26%3D+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+%28%5Cpartial_1+L+%5Ccirc+%5CGamma%5Bq%5D%29+%5Ceta+%2B+%28%5Cpartial_2+L+%5Ccirc+%5CGamma%5Bq%5D%29+D+%5Ceta+%2B+%28%5Cpartial_3+L+%5Ccirc+%5CGamma%5Bq%5D%29+D%5E2+%5Ceta+%5C%5C++++++++++++++++++++++++%26%3D+++%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+%28%5Cpartial_1+L+%5Ccirc+%5CGamma%5Bq%5D%29+%5Ceta++++++%2B+%5Cleft%5B+%5Cleft.+%28%5Cpartial_2+L+%5Ccirc+%5CGamma%5Bq%5D%29+%5Ceta+%5Cright%7C_%7Bt_1%7D%5E%7Bt_2%7D+-+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+D%28%5Cpartial_2+L+%5Ccirc+%5CGamma%5Bq%5D%29+%5Ceta+%5Cright%5D+++++%2B+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+%28%5Cpartial_3+L+%5Ccirc+%5CGamma%5Bq%5D%29+D%5E2+%5Ceta+%5C%5C++++++++++++++++++++++++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} \delta_\eta S[q] (t_1, t_2) &= \int_{t_1}^{t_2} (\partial_1 L \circ \Gamma[q]) \eta - \int_{t_1}^{t_2} D(\partial_2 L \circ \Gamma[q]) \eta + \int_{t_1}^{t_2} (\partial_3 L \circ \Gamma[q]) D^2 \eta \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++%5Cdelta_%5Ceta+S%5Bq%5D+%28t_1%2C+t_2%29+++%26%3D+++%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+%28%5Cpartial_1+L+%5Ccirc+%5CGamma%5Bq%5D%29+%5Ceta++++++-+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+D%28%5Cpartial_2+L+%5Ccirc+%5CGamma%5Bq%5D%29+%5Ceta++++++%2B+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+%28%5Cpartial_3+L+%5Ccirc+%5CGamma%5Bq%5D%29+D%5E2+%5Ceta+%5C%5C++++++++++++++++++++++++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} \delta_\eta S[q] (t_1, t_2) &= \int_{t_1}^{t_2} (\partial_1 L \circ \Gamma[q]) \eta - \int_{t_1}^{t_2} D(\partial_2 L \circ \Gamma[q]) \eta - \int_{t_1}^{t_2} D(\partial_3 L \circ \Gamma[q]) D \eta \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++%5Cdelta_%5Ceta+S%5Bq%5D+%28t_1%2C+t_2%29+++%26%3D+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+%28%5Cpartial_1+L+%5Ccirc+%5CGamma%5Bq%5D%29+%5Ceta++++++++-+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+D%28%5Cpartial_2+L+%5Ccirc+%5CGamma%5Bq%5D%29+%5Ceta++++++++-+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+D%28%5Cpartial_3+L+%5Ccirc+%5CGamma%5Bq%5D%29+D+%5Ceta+%5C%5C++++++++++++++++++++++++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} \delta_\eta S[q] (t_1, t_2) &= \int_{t_1}^{t_2} (\partial_1 L \circ \Gamma[q]) \eta - \int_{t_1}^{t_2} D(\partial_2 L \circ \Gamma[q]) \eta + \int_{t_1}^{t_2} D^2 (\partial_3 L \circ \Gamma[q]) \eta \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++%5Cdelta_%5Ceta+S%5Bq%5D+%28t_1%2C+t_2%29+++%26%3D+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+%28%5Cpartial_1+L+%5Ccirc+%5CGamma%5Bq%5D%29+%5Ceta++++++++-+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+D%28%5Cpartial_2+L+%5Ccirc+%5CGamma%5Bq%5D%29+%5Ceta++++++++%2B+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+D%5E2+%28%5Cpartial_3+L+%5Ccirc+%5CGamma%5Bq%5D%29+%5Ceta+%5C%5C++++++++++++++++++++++++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} \delta_\eta S[q] (t_1, t_2) &= \int_{t_1}^{t_2} \left[ (\partial_1 L \circ \Gamma[q]) - D(\partial_2 L \circ \Gamma[q]) + D^2 (\partial_3 L \circ \Gamma[q]) \right] \eta \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++%5Cdelta_%5Ceta+S%5Bq%5D+%28t_1%2C+t_2%29+++%26%3D+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+%5Cleft%5B+%28%5Cpartial_1+L+%5Ccirc+%5CGamma%5Bq%5D%29+-+D%28%5Cpartial_2+L+%5Ccirc+%5CGamma%5Bq%5D%29+%2B+D%5E2+%28%5Cpartial_3+L+%5Ccirc+%5CGamma%5Bq%5D%29+%5Cright%5D+%5Ceta+%5C%5C++++++++++++++++++++++++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} 0 &= \int_{t_1}^{t_2} \left[ (\partial_1 L \circ \Gamma[q]) - D(\partial_2 L \circ \Gamma[q]) + D^2 (\partial_3 L \circ \Gamma[q]) \right] \eta \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++0+++%26%3D+%5Cint_%7Bt_1%7D%5E%7Bt_2%7D+%5Cleft%5B+%28%5Cpartial_1+L+%5Ccirc+%5CGamma%5Bq%5D%29+-+D%28%5Cpartial_2+L+%5Ccirc+%5CGamma%5Bq%5D%29+%2B+D%5E2+%28%5Cpartial_3+L+%5Ccirc+%5CGamma%5Bq%5D%29+%5Cright%5D+%5Ceta+%5C%5C++++++++++++++++++++++++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} (\partial_1 L \circ \Gamma[q]) - D(\partial_2 L \circ \Gamma[q]) + D^2 (\partial_3 L \circ \Gamma[q]) &= 0 \\ D^2 (\partial_3 L \circ \Gamma[q]) - D(\partial_2 L \circ \Gamma[q]) + \partial_1 L \circ \Gamma[q] &= 0 \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+++%28%5Cpartial_1+L+%5Ccirc+%5CGamma%5Bq%5D%29+-+D%28%5Cpartial_2+L+%5Ccirc+%5CGamma%5Bq%5D%29+%2B+D%5E2+%28%5Cpartial_3+L+%5Ccirc+%5CGamma%5Bq%5D%29+%26%3D+0+%5C%5C++++++++++++++++++++++++D%5E2+%28%5Cpartial_3+L+%5Ccirc+%5CGamma%5Bq%5D%29+-+D%28%5Cpartial_2+L+%5Ccirc+%5CGamma%5Bq%5D%29+%2B+%5Cpartial_1+L+%5Ccirc+%5CGamma%5Bq%5D+%26%3D+0+%5C%5C++++++++++++++++++++++++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)

You must be logged in to post a comment.