

— DeepAI colorization
— GIMP
.
.
2020.07.24 Friday (c) All rights reserved by ACHK

— DeepAI colorization
— GIMP
.
.
2020.07.24 Friday (c) All rights reserved by ACHK
A First Course in String Theory
.
2.3 Lorentz transformations, derivatives, and quantum operators.
(b) Show that the objects 


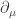
~~~
The Lorentz transformation:
Lowering the indices to create covariant vectors:
In matrix form, covariant vectors are represented by row vectors:
Change the subject:
With ![\displaystyle{ \begin{aligned} \eta^{\mu \nu} &\stackrel{\text{\tiny def}}{=} \left[ \eta_{\mu \nu} \right]^{-1} \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D++%5Ceta%5E%7B%5Cmu+%5Cnu%7D+%26%5Cstackrel%7B%5Ctext%7B%5Ctiny+def%7D%7D%7B%3D%7D+%5Cleft%5B+%5Ceta_%7B%5Cmu+%5Cnu%7D+%5Cright%5D%5E%7B-1%7D+++%5C%5C++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
Now we lower the indices in order to find the Lorentz transformation for the covariant components:
…
— Me@2020-07-21 10:46:32 AM
.
.
2020.07.22 Wednesday (c) All rights reserved by ACHK
What’s sneaky about quantum mechanics is that the whole system can be in a pure state which when restricted to each subsystem gives a mixed state, and that these mixed states are then correlated (necessarily, as it turns out). That’s what “entanglement” is all about.
…
The first way things get trickier in quantum mechanics is that something we are used to in classical mechanics fails. In classical mechanics, pure states are always dispersion-free — that is, for every observable, the probability measure assigned by the state to that observable is a Dirac delta measure, that is, the observable has a 100% chance of being some specific value and a 0% chance of having any other value. (Consider the example of the dice, with the observable being the number of dots on the face pointing up.) In quantum mechanics, pure states need NOT be dispersion-free. In fact, they usually aren’t.
A second, subtler way things get trickier in quantum mechanics concerns systems made of parts, or subsystems. Every observable of a subsystem is automatically an observable for the whole system (but not all observables of the whole system are of that form; some involve, say, adding observables of two different subsystems). So every state of the whole system gives rise to, or as we say, “restricts to,” a state of each of its subsystems. In classical mechanics, pure states restrict to pure states. For example, if our system consisted of 2 dice, a pure state of the whole system would be something like “the first die is in state 2 and the second one is in state 5;” this restricts to a pure state for the first die (state 2) and a pure state for the second die (state 5). In quantum mechanics, it is not true that a pure state of a system must restrict to a pure state of each subsystem.
It is this latter fact that gave rise to a whole bunch of quantum puzzles such as the Einstein-Podolsky-Rosen puzzle and Bell’s inequality. And it is this last fact that makes things a bit tricky when one of the two subsystems happens to be you. It is possible, and indeed very common, for the following thing to happen when two subsystems interact as time passes. Say the whole system starts out in a pure state which restricts to a pure state of each subsystem. After a while, this need no longer be the case! Namely, if we solve Schroedinger’s equation to calculate the state of the system a while later, it will necessarily still be a pure state (pure states of the whole system evolve to pure states), but it need no longer restrict to pure states of the two subsystems. If this happens, we say that the two subsystems have become “entangled.”
— December 16, 1993
— This Week’s Finds in Mathematical Physics (Week 27)
— John Baez
.
.
2020.07.19 Sunday ACHK
We talked half the night, and in the middle of talk became lovers.
— Bertrand Russell
.
.
2020.07.18 Saturday ACHK
這段改編自 2010 年 4 月 18 日的對話。
.
那就有如在該門知識中,你已經找齊七粒龍珠,「神龍」出現了,你可以實現任何願望。
所以,其實不用太緊張。與其懼怕有所遺漏,倒不如活在當下,享受獲取知識的過程。根本,並沒有需要,去窮盡「所有」的書籍。正如,學習英文時,你有需要學懂,英文字典中的所有詞匯嗎?
The man who grasps principles can successfully select his own methods. The man who tries methods, ignoring principles, is sure to have trouble.
— Ralph Waldo Emerson
任何一門知識,起點都是「學海無涯,唯勤是岸」,終點都是「學海無涯,回頭是岸」。
「通用知識」的意思是,每人日常也需要知道的東西,例如,健康、財政、人際、時間管理等。
As we get older, generic reading becomes less and less useful. We then gain new knowledge mostly by personal life experience and directed reading.
— paraphrasing John T. Reed
那是指一般「通用知識」。
至於「專業知識」,即是「技術細節」,結構和「通用知識」雖有相似之處,但不大一樣。
— Me@2020-07-16 06:14:51 PM
.
.
2020.07.17 Friday (c) All rights reserved by ACHK

— Me@2020-07-15 05:14:08 PM
.
.
2020.07.15 Wednesday (c) All rights reserved by ACHK
Ex 1.8.2.3, Structure and Interpretation of Classical Mechanics
.
— Me@2020-07-14 06:00:35 PM
.
.
2020.07.15 Wednesday (c) All rights reserved by ACHK
You cannot go through time without changing (the definition of) yourself.
— Me@2012.04.28
.
.
2020.07.12 Sunday (c) All rights reserved by ACHK
釋放自我,個自我走甩咗。
點算?
— Me@2011.06.24
.
.
2020.07.11 Saturday (c) All rights reserved by ACHK
中六時,我日校的同學中,有些在中五時和我一樣,都是補 Ken Chan 的物理班。升上中六後,他們大部分也補 MC Chan 的物理班。我在中六時則沒有補習。我在中六升中七的暑假,才去上 MC Chan 的物理班。
我的那個年代,有很多補習班也以「貼中考試題目」作為招徠。有一次上課時,MC Chan 說:
「
如果到咗呢個時候,你仍然相信,世間上有『貼士』嘅話,咁你都無資格讀大學啦。
」
(如果到了這個時候,你仍然相信,世間上有『貼士』的話,你大概沒有資格讀大學吧。)
他說,出題人員有著極高的月薪(當年七萬多港元)。他們根本沒有任何動機去貪污。
他又解釋,他當年所謂的「貼中」題目,是如何達成的。當年他在高考前,預測題目會有「光電效應」。結果,有一題長題目,真的是考「光電效應」。而方法則很簡單,就是每年也預測同一個課題。他每年也預測「光電效應」,總有一年會「貼中」。然後補習社就可以,大肆宣傳。
.
其實,根本不用他提點,一般人只要冷靜一點,也可以想到,「貼士」近乎沒有可能。
第一,如果有一位補習導師的「貼題」命中率,真的十分高的話,他為何還未被廉政公署拘捕呢?
第二,或者有人會為他辯護:「可能他有超能力,能知過去未來。運用超能力,是完全合法的。」
如果是那樣的話,他在公開試前,開幾堂就可以;為何一科要上那麼多堂,收我那麼多學費?
.
即使命中了題目,那代表你會懂答嗎?
即使命中了題目,那代表單憑該題的分數,你就會有上乘成績嗎?
— Me@2020-07-10 04:13:13 PM
.
.
2020.07.10 Friday (c) All rights reserved by ACHK
First photo, 2
.

— Me@2020-07-06 09:08:48 PM
.
.
2020.07.06 Monday (c) All rights reserved by ACHK
A First Course in String Theory
.
2.2 Lorentz transformations, derivatives, and quantum operators.
(a) Give the Lorentz transformations for the components 

~~~
.
Another method is to start with:
— Me@2020-07-05 05:40:44 PM
.
.
2020.07.05 Sunday (c) All rights reserved by ACHK
observer ~ a consistent description
— Me@2017-08-03 07:58:50 AM
.
.
2020.07.04 Saturday (c) All rights reserved by ACHK
Do not let what you cannot do interfere with what you can do.
— John Wooden
.
.
2020.06.30 Tuesday ACHK



![\displaystyle{ \begin{aligned} \left[ x_\mu \right] &= \left( [\eta_{\mu \nu}] [x^\nu] \right)^T \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D++%5Cleft%5B+x_%5Cmu+%5Cright%5D+%26%3D+%5Cleft%28+%5B%5Ceta_%7B%5Cmu+%5Cnu%7D%5D+%5Bx%5E%5Cnu%5D+%5Cright%29%5ET+%5C%5C++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} \left[ x_\mu \right]^T &= [\eta_{\mu \nu}] [x^\nu] \\ [\eta_{\mu \nu}] [x^\nu] &= \left[ x_\mu \right]^T \\ [x^\nu] &= [\eta_{\mu \nu}]^{-1} \left[ x_\mu \right]^T \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D++%5Cleft%5B+x_%5Cmu+%5Cright%5D%5ET+%26%3D+%5B%5Ceta_%7B%5Cmu+%5Cnu%7D%5D+%5Bx%5E%5Cnu%5D+%5C%5C++%5B%5Ceta_%7B%5Cmu+%5Cnu%7D%5D+%5Bx%5E%5Cnu%5D+%26%3D+%5Cleft%5B+x_%5Cmu+%5Cright%5D%5ET++%5C%5C++%5Bx%5E%5Cnu%5D+%26%3D+%5B%5Ceta_%7B%5Cmu+%5Cnu%7D%5D%5E%7B-1%7D+%5Cleft%5B+x_%5Cmu+%5Cright%5D%5ET++%5C%5C++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\displaystyle{ \begin{aligned} \left[ x^\nu \right] &= \left[ \eta^{\mu \nu} \right] \left[ x_\mu \right]^T \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D++%5Cleft%5B+x%5E%5Cnu+%5Cright%5D+%26%3D+%5Cleft%5B+%5Ceta%5E%7B%5Cmu+%5Cnu%7D+%5Cright%5D+%5Cleft%5B+x_%5Cmu+%5Cright%5D%5ET++%5C%5C++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)


![\displaystyle{ \begin{aligned} &\delta_\eta F[g[q]] \\ &= \delta_\eta (F \circ g)[q] \\ &= \lim_{\epsilon \to 0} \left( \frac{F[g[q + \epsilon \eta]] - F[g[q]]}{\epsilon} \right) \\ &= \lim_{\epsilon \to 0} \left( \frac{F[g[q] + \epsilon \delta_\eta g[q] + \epsilon^2 (...) + \epsilon^3 (...) + ...]] - F[g[q]]}{\epsilon} \right) \\ &= \lim_{\epsilon \to 0} \left( \frac{F[g[q] + \epsilon \delta_\eta g[q] + \epsilon^2 (... + \epsilon (...) + ...)]] - F[g[q]]}{\epsilon} \right) \\ &= \lim_{\epsilon \to 0} \left( \frac{F[g[q] + \epsilon \delta_\eta g[q] + \epsilon^2 (...)]] - F[g[q]]}{\epsilon} \right) \\ &= \lim_{\epsilon \to 0} \left( \frac{F[g[q] + \epsilon \left(\delta_\eta g[q] + \epsilon (...)\right)]] - F[g[q]]}{\epsilon} \right) \\ &= \lim_{\epsilon \to 0} \left( \frac{F[g[q]] + \epsilon \delta_{\left(\delta_\eta g[q] + \epsilon (...)\right)} F[g[q]] + \epsilon^2 (...) - F[g[q]]}{\epsilon} \right) \\ &= \lim_{\epsilon \to 0} \left( \frac{\epsilon \delta_{\left(\delta_\eta g[q] + \epsilon (...)\right)} F[g[q]] + \epsilon^2 (...)}{\epsilon} \right) \\ &= \lim_{\epsilon \to 0} \left( \delta_{\left(\delta_\eta g[q] + \epsilon (...)\right)} F[g[q]] + \epsilon (...) \right) \\ &= \delta_{ \left( \delta_\eta g[q] \right)} F[g] \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D++%26%5Cdelta_%5Ceta+F%5Bg%5Bq%5D%5D+%5C%5C+%26%3D+%5Cdelta_%5Ceta+%28F+%5Ccirc+g%29%5Bq%5D+%5C%5C++%26%3D+%5Clim_%7B%5Cepsilon+%5Cto+0%7D++%5Cleft%28+%5Cfrac%7BF%5Bg%5Bq+%2B+%5Cepsilon+%5Ceta%5D%5D+-+F%5Bg%5Bq%5D%5D%7D%7B%5Cepsilon%7D+%5Cright%29+%5C%5C++%26%3D+%5Clim_%7B%5Cepsilon+%5Cto+0%7D++%5Cleft%28+%5Cfrac%7BF%5Bg%5Bq%5D+%2B+%5Cepsilon+%5Cdelta_%5Ceta+g%5Bq%5D+%2B+%5Cepsilon%5E2+%28...%29+%2B+%5Cepsilon%5E3+%28...%29+%2B+...%5D%5D+-+F%5Bg%5Bq%5D%5D%7D%7B%5Cepsilon%7D+%5Cright%29+%5C%5C++%26%3D+%5Clim_%7B%5Cepsilon+%5Cto+0%7D++%5Cleft%28+%5Cfrac%7BF%5Bg%5Bq%5D+%2B+%5Cepsilon+%5Cdelta_%5Ceta+g%5Bq%5D+%2B+%5Cepsilon%5E2+%28...+%2B+%5Cepsilon+%28...%29+%2B+...%29%5D%5D+-+F%5Bg%5Bq%5D%5D%7D%7B%5Cepsilon%7D+%5Cright%29+%5C%5C++%26%3D+%5Clim_%7B%5Cepsilon+%5Cto+0%7D++%5Cleft%28+%5Cfrac%7BF%5Bg%5Bq%5D+%2B+%5Cepsilon+%5Cdelta_%5Ceta+g%5Bq%5D+%2B+%5Cepsilon%5E2+%28...%29%5D%5D+-+F%5Bg%5Bq%5D%5D%7D%7B%5Cepsilon%7D+%5Cright%29+%5C%5C++%26%3D+%5Clim_%7B%5Cepsilon+%5Cto+0%7D++%5Cleft%28+%5Cfrac%7BF%5Bg%5Bq%5D+%2B+%5Cepsilon+%5Cleft%28%5Cdelta_%5Ceta+g%5Bq%5D+%2B+%5Cepsilon+%28...%29%5Cright%29%5D%5D+-+F%5Bg%5Bq%5D%5D%7D%7B%5Cepsilon%7D+%5Cright%29+%5C%5C++%26%3D+%5Clim_%7B%5Cepsilon+%5Cto+0%7D++%5Cleft%28+%5Cfrac%7BF%5Bg%5Bq%5D%5D+%2B+%5Cepsilon+%5Cdelta_%7B%5Cleft%28%5Cdelta_%5Ceta+g%5Bq%5D+%2B+%5Cepsilon+%28...%29%5Cright%29%7D+F%5Bg%5Bq%5D%5D+%2B+%5Cepsilon%5E2+%28...%29+-+F%5Bg%5Bq%5D%5D%7D%7B%5Cepsilon%7D+%5Cright%29+%5C%5C++%26%3D+%5Clim_%7B%5Cepsilon+%5Cto+0%7D++%5Cleft%28+%5Cfrac%7B%5Cepsilon+%5Cdelta_%7B%5Cleft%28%5Cdelta_%5Ceta+g%5Bq%5D+%2B+%5Cepsilon+%28...%29%5Cright%29%7D+F%5Bg%5Bq%5D%5D+%2B+%5Cepsilon%5E2+%28...%29%7D%7B%5Cepsilon%7D+%5Cright%29+%5C%5C++%26%3D+%5Clim_%7B%5Cepsilon+%5Cto+0%7D++%5Cleft%28+%5Cdelta_%7B%5Cleft%28%5Cdelta_%5Ceta+g%5Bq%5D+%2B+%5Cepsilon+%28...%29%5Cright%29%7D+F%5Bg%5Bq%5D%5D+%2B+%5Cepsilon+%28...%29+%5Cright%29+%5C%5C++%26%3D+%5Cdelta_%7B+%5Cleft%28+%5Cdelta_%5Ceta+g%5Bq%5D+%5Cright%29%7D+F%5Bg%5D+%5C%5C++%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)
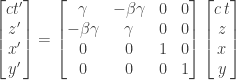
![\displaystyle{ \begin{aligned} (x')^\mu &= L^\mu_{~\nu} x^\nu \\ a_\mu &= a^\nu \eta_{\mu \nu} \\ (a')_\mu &= L_\mu^{~\nu} a_\nu \\ [(a')_\mu] &= [a_\nu] [L^\mu_{~\nu}]^{-1} \\ [L^\mu_{~\nu}]^{-1} &= \begin{bmatrix} \gamma & \beta \gamma & 0 & 0 \\ \beta \gamma & \gamma & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \\ \end{bmatrix} \\ \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B+%5Cbegin%7Baligned%7D+%28x%27%29%5E%5Cmu+%26%3D+L%5E%5Cmu_%7B%7E%5Cnu%7D+x%5E%5Cnu+%5C%5C+a_%5Cmu+%26%3D+a%5E%5Cnu+%5Ceta_%7B%5Cmu+%5Cnu%7D+%5C%5C+%28a%27%29_%5Cmu+%26%3D+L_%5Cmu%5E%7B%7E%5Cnu%7D+a_%5Cnu+%5C%5C+%5B%28a%27%29_%5Cmu%5D+%26%3D+%5Ba_%5Cnu%5D+%5BL%5E%5Cmu_%7B%7E%5Cnu%7D%5D%5E%7B-1%7D+%5C%5C+%5BL%5E%5Cmu_%7B%7E%5Cnu%7D%5D%5E%7B-1%7D+%26%3D+%5Cbegin%7Bbmatrix%7D+%5Cgamma+%26+%5Cbeta+%5Cgamma+%26+0+%26+0+%5C%5C+%5Cbeta+%5Cgamma+%26+%5Cgamma+%26+0+%26+0+%5C%5C+0+%26+0+%26+1+%26+0+%5C%5C+0+%26+0+%26+0+%26+1+%5C%5C+%5Cend%7Bbmatrix%7D+%5C%5C+%5Cend%7Baligned%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002)

You must be logged in to post a comment.