p_27 = -(2 * a - 1) * (a ^ 2 - a + 41)
where
n = 1000
m = head $ filter (\x -> x ^ 2 - x + 41 > n) [1 ..]
a = m - 1
Euler Problem 27 asks us to find a quadratic equation of the form  that generates the most consecutive prime numbers starting from
that generates the most consecutive prime numbers starting from  , with the constraints
, with the constraints  and
and  . The final answer is the product
. The final answer is the product  for the winning pair. The “official” Haskell solution looks cryptic, but there’s a clever trick behind it. Let’s break it down step-by-step in a way that’s easier to follow.
for the winning pair. The “official” Haskell solution looks cryptic, but there’s a clever trick behind it. Let’s break it down step-by-step in a way that’s easier to follow.
A Handy Math Trick: Shifting the Quadratic
Imagine we tweak our quadratic by replacing 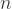 with
with  . When we expand it out, we get:
. When we expand it out, we get:

This is still a quadratic in , but now the coefficients are:
By choosing the right  , we can transform any quadratic into a simpler form, like
, we can transform any quadratic into a simpler form, like  or
or  . This is our starting point.
. This is our starting point.

Which Form Works Best?
- Form 1:
This one’s a dud. Plug in  , and you’ll see every other number is even (e.g.,
, and you’ll see every other number is even (e.g.,  ). With so many evens, it can’t produce a long run of primes—primes are mostly odd (except 2).
). With so many evens, it can’t produce a long run of primes—primes are mostly odd (except 2).
- Form 2:
This is more promising. A mathematician named Rabinowitz proved that for this form to generate the longest sequence of primes,  must be a special number called a Heegner number. There are only six possibilities, and after testing,
must be a special number called a Heegner number. There are only six possibilities, and after testing,  comes out on top. It spits out 40 primes from to
comes out on top. It spits out 40 primes from to  . The runner-up,
. The runner-up,  , doesn’t do as well.
, doesn’t do as well.
So, is our golden ticket. But there’s more to it.
The Symmetry Bonus
Here’s a cool trick with :

This means if  gives a prime (like 47), then
gives a prime (like 47), then  (i.e.,
(i.e.,  ) does too (also 47). The sequence works both ways—positive and negative . Starting at , we get 40 primes up to , but we can also count backward with negative . Our goal is to shift this quadratic so we capture more of these primes from onward, while keeping
) does too (also 47). The sequence works both ways—positive and negative . Starting at , we get 40 primes up to , but we can also count backward with negative . Our goal is to shift this quadratic so we capture more of these primes from onward, while keeping  and
and  within the problem’s limits.
within the problem’s limits.

Fitting It Into the Rules
Let’s start with (where  ) and shift it using our trick:
) and shift it using our trick:
The problem says and , so:
The second condition is trickier because  grows fast. We need the biggest where
grows fast. We need the biggest where  .
.

Crunching the Numbers
Let’s test some values:
 :
:  (under 1000)
(under 1000) :
:  (over 1000)
(over 1000)
So, is the largest value that works. Now calculate:

 (from above)
(from above)
Check the constraints:
 ✓
✓ ✓
✓

The Haskell Code Explained
That’s where this funky code comes in:
n = 1000
m = head $ filter (\x -> x ^ 2 - x + 41 > n) [1 ..]
a = m - 1
It finds  (first where
(first where  ). Then
). Then  .
.
The final line:
p_27 = -(2 * a - 1) * (a ^ 2 - a + 41)
This is a bit off. It uses  , but we need
, but we need  . The correct product should be:
. The correct product should be:
The code’s formula seems to be a typo or a leftover from a different derivation. It should just compute  .
.

Why It Works
With  , the quadratic
, the quadratic  generates 71 primes from to
generates 71 primes from to  . This shift captures more of the sequence’s primes in the positive direction, thanks to the negative . The product -59231 is the answer.
. This shift captures more of the sequence’s primes in the positive direction, thanks to the negative . The product -59231 is the answer.
Wrapping Up
This solution is sneaky—it starts with a prime-generating champ, shifts it just right, and fits the problem’s rules. It’s not the brute-force way (testing every and ), but a math shortcut that lands on the perfect answer. Pretty cool, right?
— Me@2025-03-24 12:25:20 PM
.
.
2025.03.30 Sunday (c) All rights reserved by ACHK



















![\bar f[q]](https://s0.wp.com/latex.php?latex=%5Cbar+f%5Bq%5D&bg=ffffff&fg=333333&s=1&c=20201002) and the path function
and the path function ![\bar \Gamma (\bar f) \circ \Gamma [q]](https://s0.wp.com/latex.php?latex=%5Cbar+%5CGamma+%28%5Cbar+f%29+%5Ccirc+%5CGamma+%5Bq%5D&bg=ffffff&fg=333333&s=1&c=20201002) are not necessarily the same. Explain.
are not necessarily the same. Explain.

 -th derivative are said to osculate with order-
-th derivative are said to osculate with order-






![[ \bar{N}^\perp, \bar{\alpha}_{- \frac{q}{2}} ] = \frac{q}{2} \bar{\alpha}_{- \frac{q}{2}}](https://s0.wp.com/latex.php?latex=%5B+%5Cbar%7BN%7D%5E%5Cperp%2C+%5Cbar%7B%5Calpha%7D_%7B-+%5Cfrac%7Bq%7D%7B2%7D%7D+%5D+%3D+%5Cfrac%7Bq%7D%7B2%7D+%5Cbar%7B%5Calpha%7D_%7B-+%5Cfrac%7Bq%7D%7B2%7D%7D&bg=ffffff&fg=333333&s=1&c=20201002) and explain why
and explain why  is properly called a number operator.
is properly called a number operator.
![\left[ \bar \alpha_{\frac{m}{2}}, \bar \alpha_{\frac{n}{2}} \right] = \frac{m}{2} \delta_{m+n, 0}](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbar+%5Calpha_%7B%5Cfrac%7Bm%7D%7B2%7D%7D%2C+%5Cbar+%5Calpha_%7B%5Cfrac%7Bn%7D%7B2%7D%7D+%5Cright%5D+%3D+%5Cfrac%7Bm%7D%7B2%7D+%5Cdelta_%7Bm%2Bn%2C+0%7D&bg=ffffff&fg=333333&s=1&c=20201002)
![[AB,C]=A[B,C]+[A,C]B](https://s0.wp.com/latex.php?latex=%5BAB%2CC%5D%3DA%5BB%2CC%5D%2B%5BA%2CC%5DB&bg=ffffff&fg=333333&s=1&c=20201002)
![\begin{aligned} &[ \bar{N}^\perp, \bar{\alpha}_{- \frac{q}{2}} ] \\ &= \sum_{p=1}^{\infty} [ \bar \alpha^i_{-p} \bar \alpha^i_{~p}, \bar{\alpha}_{- \frac{q}{2}} ] + \sum_{k \in \mathbb{Z}^+_\text{odd}} [ \bar \alpha_{- \frac{k}{2}} \bar \alpha_{\frac{k}{2}}, \bar{\alpha}_{- \frac{q}{2}} ] \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++%26%5B+%5Cbar%7BN%7D%5E%5Cperp%2C+%5Cbar%7B%5Calpha%7D_%7B-+%5Cfrac%7Bq%7D%7B2%7D%7D+%5D+%5C%5C++%26%3D+%5Csum_%7Bp%3D1%7D%5E%7B%5Cinfty%7D+%5B+%5Cbar+%5Calpha%5Ei_%7B-p%7D+%5Cbar+%5Calpha%5Ei_%7B%7Ep%7D%2C+%5Cbar%7B%5Calpha%7D_%7B-+%5Cfrac%7Bq%7D%7B2%7D%7D+%5D+%2B+%5Csum_%7Bk+%5Cin+%5Cmathbb%7BZ%7D%5E%2B_%5Ctext%7Bodd%7D%7D+%5B+%5Cbar+%5Calpha_%7B-+%5Cfrac%7Bk%7D%7B2%7D%7D+%5Cbar+%5Calpha_%7B%5Cfrac%7Bk%7D%7B2%7D%7D%2C+%5Cbar%7B%5Calpha%7D_%7B-+%5Cfrac%7Bq%7D%7B2%7D%7D+%5D++%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=1&c=20201002)
 ,
,![[\bar{N}^\perp, \bar{\alpha}_{- \frac{q}{2}} ] = 0](https://s0.wp.com/latex.php?latex=%5B%5Cbar%7BN%7D%5E%5Cperp%2C+%5Cbar%7B%5Calpha%7D_%7B-+%5Cfrac%7Bq%7D%7B2%7D%7D+%5D+%3D+0&bg=ffffff&fg=333333&s=1&c=20201002)
 ,
,![\begin{aligned} &[ \bar{N}^\perp, \bar{\alpha}_{- \frac{q}{2}} ] \\ &= \sum_{k \in \mathbb{Z}^+_\text{odd}}\left( \bar \alpha_{- \frac{k}{2}} [ \bar \alpha_{\frac{k}{2}}, \bar{\alpha}_{- \frac{q}{2}} ] + [ \bar \alpha_{- \frac{k}{2}}, \bar{\alpha}_{- \frac{q}{2}} ] \bar \alpha_{\frac{k}{2}} \right) \\ &= \sum_{k \in \mathbb{Z}^+_\text{odd}}\left( \bar \alpha_{- \frac{k}{2}} [ \bar \alpha_{\frac{k}{2}}, \bar{\alpha}_{- \frac{q}{2}} ] \right) + 0 \\ &= \bar \alpha_{- \frac{q}{2}} [ \bar \alpha_{\frac{q}{2}}, \bar{\alpha}_{- \frac{q}{2}} ] \\ &= \bar \alpha_{- \frac{q}{2}} \frac{q}{2} \\ \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++%26%5B+%5Cbar%7BN%7D%5E%5Cperp%2C+%5Cbar%7B%5Calpha%7D_%7B-+%5Cfrac%7Bq%7D%7B2%7D%7D+%5D+%5C%5C++%26%3D+%5Csum_%7Bk+%5Cin+%5Cmathbb%7BZ%7D%5E%2B_%5Ctext%7Bodd%7D%7D%5Cleft%28+++%5Cbar+%5Calpha_%7B-+%5Cfrac%7Bk%7D%7B2%7D%7D+%5B++%5Cbar+%5Calpha_%7B%5Cfrac%7Bk%7D%7B2%7D%7D%2C+%5Cbar%7B%5Calpha%7D_%7B-+%5Cfrac%7Bq%7D%7B2%7D%7D+%5D+++%2B+%5B+%5Cbar+%5Calpha_%7B-+%5Cfrac%7Bk%7D%7B2%7D%7D%2C+%5Cbar%7B%5Calpha%7D_%7B-+%5Cfrac%7Bq%7D%7B2%7D%7D+%5D+%5Cbar+%5Calpha_%7B%5Cfrac%7Bk%7D%7B2%7D%7D+%5Cright%29++%5C%5C++%26%3D+%5Csum_%7Bk+%5Cin+%5Cmathbb%7BZ%7D%5E%2B_%5Ctext%7Bodd%7D%7D%5Cleft%28+++%5Cbar+%5Calpha_%7B-+%5Cfrac%7Bk%7D%7B2%7D%7D+%5B++%5Cbar+%5Calpha_%7B%5Cfrac%7Bk%7D%7B2%7D%7D%2C+%5Cbar%7B%5Calpha%7D_%7B-+%5Cfrac%7Bq%7D%7B2%7D%7D+%5D+%5Cright%29++%2B+0++%5C%5C++%26%3D++++%5Cbar+%5Calpha_%7B-+%5Cfrac%7Bq%7D%7B2%7D%7D+%5B++%5Cbar+%5Calpha_%7B%5Cfrac%7Bq%7D%7B2%7D%7D%2C+%5Cbar%7B%5Calpha%7D_%7B-+%5Cfrac%7Bq%7D%7B2%7D%7D+%5D+++%5C%5C++%26%3D++++%5Cbar+%5Calpha_%7B-+%5Cfrac%7Bq%7D%7B2%7D%7D+%5Cfrac%7Bq%7D%7B2%7D++%5C%5C++%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=1&c=20201002)
 ,
,![\begin{aligned} &[ \bar{N}^\perp, \bar{\alpha}_{- \frac{q}{2}} ] \\ &= \sum_{k \in \mathbb{Z}^+_\text{odd}}\left( \bar \alpha_{- \frac{k}{2}} [ \bar \alpha_{\frac{k}{2}}, \bar{\alpha}_{- \frac{q}{2}} ] + [ \bar \alpha_{- \frac{k}{2}}, \bar{\alpha}_{- \frac{q}{2}} ] \bar \alpha_{\frac{k}{2}} \right) \\ &= 0 + \sum_{k \in \mathbb{Z}^+_\text{odd}} + [ \bar \alpha_{- \frac{k}{2}}, \bar{\alpha}_{- \frac{q}{2}} ] \bar \alpha_{\frac{k}{2}} \\ &= \frac{q}{2} \bar \alpha_{\frac{-q}{2}} \\ \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++%26%5B+%5Cbar%7BN%7D%5E%5Cperp%2C+%5Cbar%7B%5Calpha%7D_%7B-+%5Cfrac%7Bq%7D%7B2%7D%7D+%5D+%5C%5C++%26%3D+%5Csum_%7Bk+%5Cin+%5Cmathbb%7BZ%7D%5E%2B_%5Ctext%7Bodd%7D%7D%5Cleft%28+++%5Cbar+%5Calpha_%7B-+%5Cfrac%7Bk%7D%7B2%7D%7D+%5B++%5Cbar+%5Calpha_%7B%5Cfrac%7Bk%7D%7B2%7D%7D%2C+%5Cbar%7B%5Calpha%7D_%7B-+%5Cfrac%7Bq%7D%7B2%7D%7D+%5D+++%2B+%5B+%5Cbar+%5Calpha_%7B-+%5Cfrac%7Bk%7D%7B2%7D%7D%2C+%5Cbar%7B%5Calpha%7D_%7B-+%5Cfrac%7Bq%7D%7B2%7D%7D+%5D+%5Cbar+%5Calpha_%7B%5Cfrac%7Bk%7D%7B2%7D%7D+%5Cright%29++%5C%5C++%26%3D+0+%2B+%5Csum_%7Bk+%5Cin+%5Cmathbb%7BZ%7D%5E%2B_%5Ctext%7Bodd%7D%7D++%2B+%5B+%5Cbar+%5Calpha_%7B-+%5Cfrac%7Bk%7D%7B2%7D%7D%2C+%5Cbar%7B%5Calpha%7D_%7B-+%5Cfrac%7Bq%7D%7B2%7D%7D+%5D+%5Cbar+%5Calpha_%7B%5Cfrac%7Bk%7D%7B2%7D%7D+++%5C%5C++%26%3D++++%5Cfrac%7Bq%7D%7B2%7D+%5Cbar+%5Calpha_%7B%5Cfrac%7B-q%7D%7B2%7D%7D++%5C%5C++%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=1&c=20201002)
![[ \bar{N}^\perp, \cdot ]](https://s0.wp.com/latex.php?latex=%5B+%5Cbar%7BN%7D%5E%5Cperp%2C+%5Ccdot+%5D&bg=ffffff&fg=333333&s=1&c=20201002) should be.
should be. operators.
operators.




 is just the meaning of the definition of
is just the meaning of the definition of  . The second factor is needed because the input of
. The second factor is needed because the input of  .
.
 is just the definition of
is just the definition of  .
. is the direction derivative of the function
is the direction derivative of the function  at the point
at the point  .
.

 ‘s and
‘s and  ‘s represent the amount and direction of changes respectively.
‘s represent the amount and direction of changes respectively.


You must be logged in to post a comment.